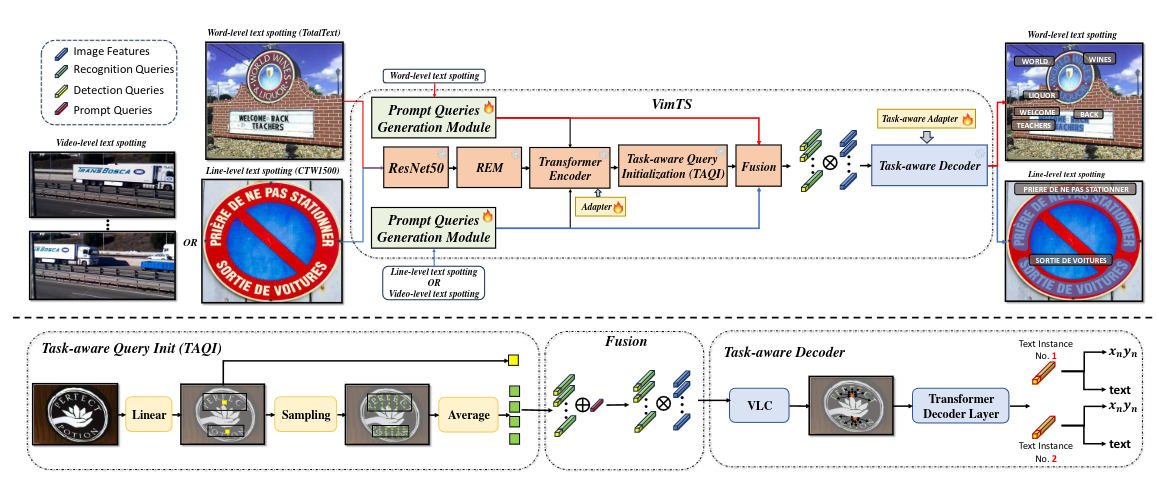
Overall framework of our method.
Overall framework of CoDeF-based synthetic method.
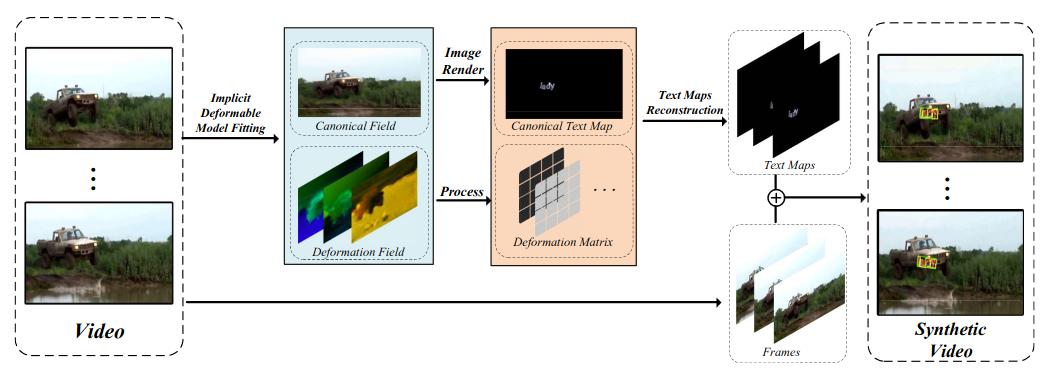
We manually collect and filter text-free, open-source and unrestricted videos from NExT-QA, Charades-Ego, Breakfast, A2D, MPI-Cooking, ActorShift and Hollywood. By utilizing the CoDeF, our synthetic method facilitates the achievement of realistic and stable text flow propagation, significantly reducing the occurrence of distortions.

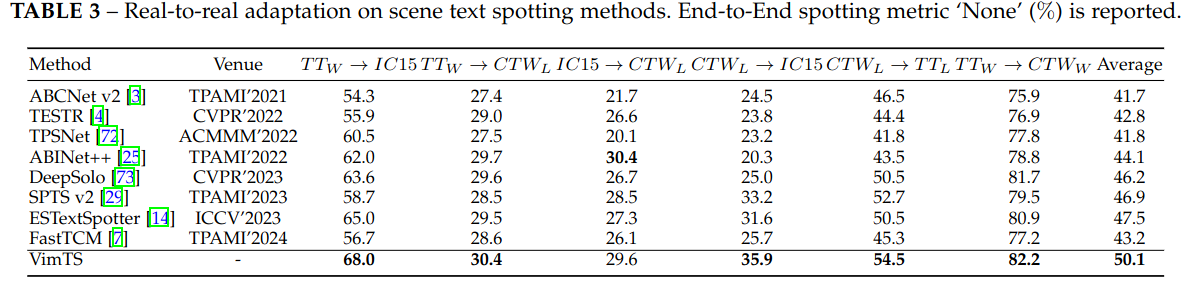
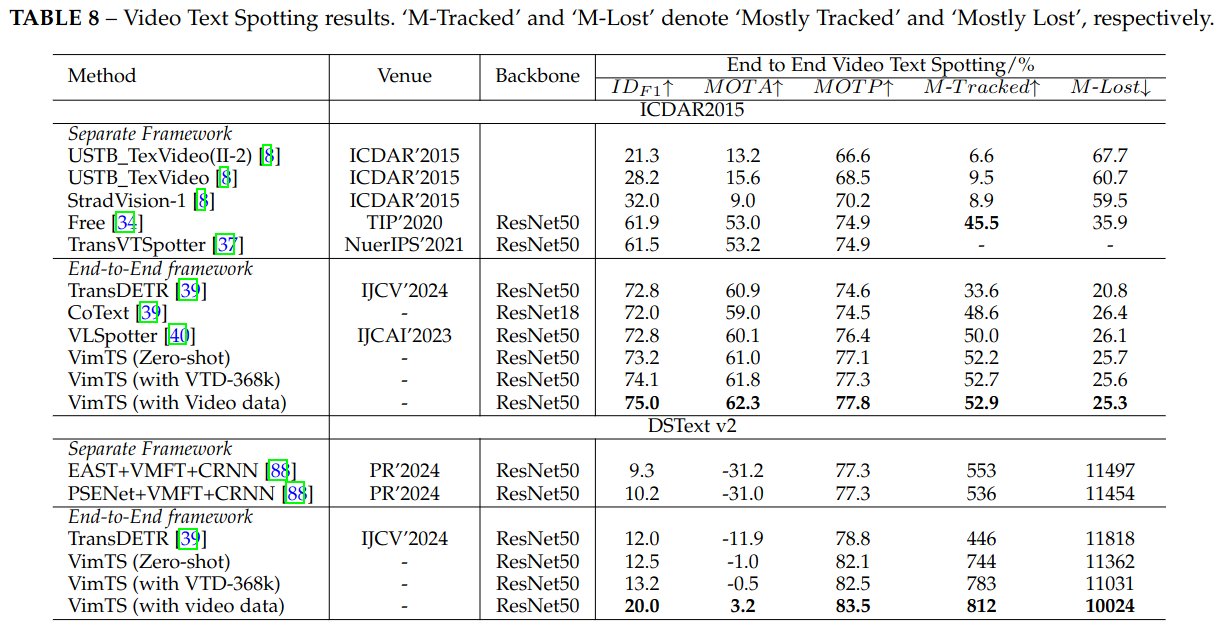
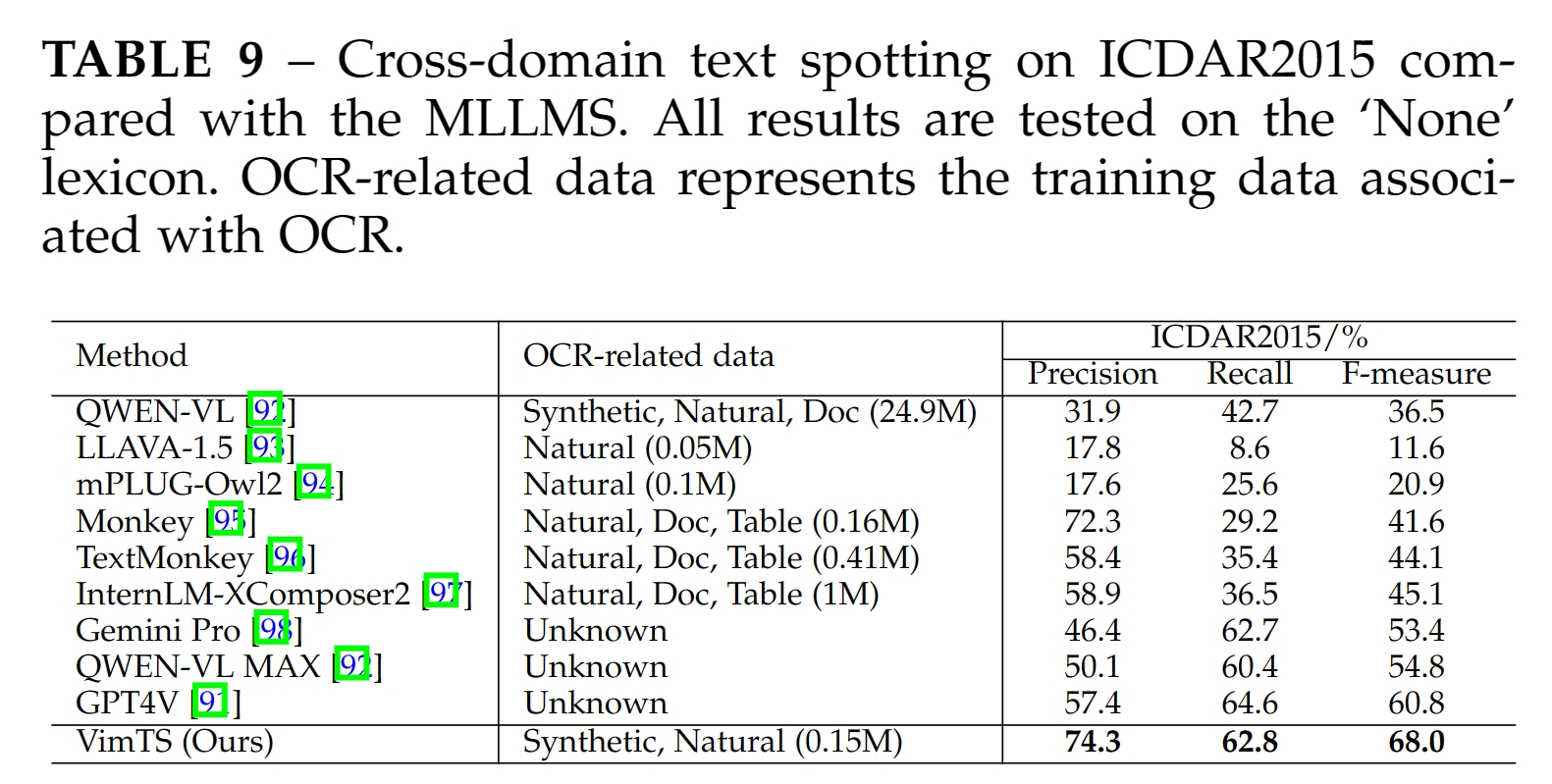
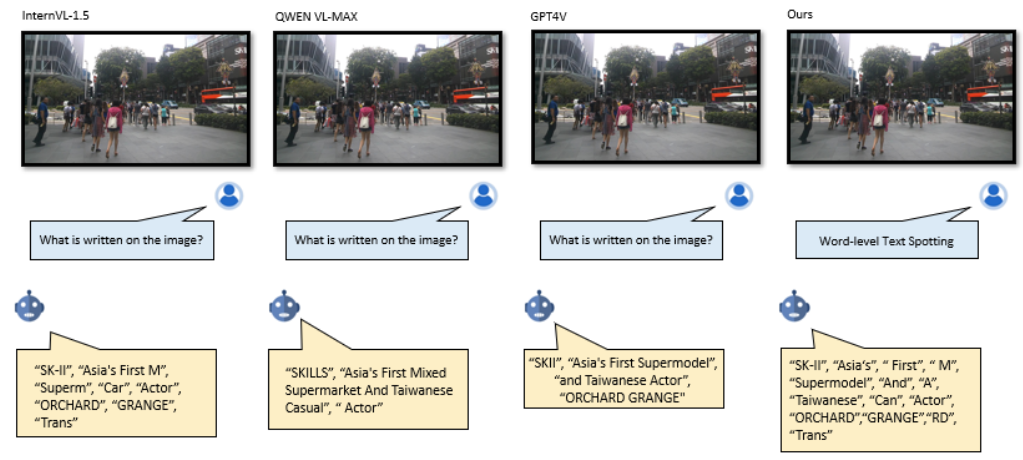
For image-level cross-domain text spotting, we conduct experiments on six cross-domain scenarios to evaluate VimTS. For video-level cross-domain text spotting, we conduct experiments on two popular video text spotting benchmarks to evaluate VimTS. The results are presented in the following.

@misc{liuvimts,
author={Liu, Yuliang and Huang, Mingxin and Yan, Hao and Deng, Linger and Wu, Weijia and Lu, Hao and Shen, Chunhua and Jin, Lianwen and Bai, Xiang},
title={VimTS: A Unified Video and Image Text Spotter for Enhancing the Cross-domain Generalization},
publisher={arXiv preprint arXiv:2404.19652},
year={2024},
}